特征降维算法总结比较
特征降维有利于减少描述 分为特征提取与特征的选择.这两者是有区别的
特征提取指对特征进行某种变换,得到新特征; 特征选择指通过某些方法获取特征的子集. 这篇文章是对以上两者的总结.
- 1 特征提取 (Feature extration)
- 2 特征选择 (Feature selection)
- 2.1 剔除低方差特征 (Removing features with low variance)
- 2.2 单变量特征选择 (Univariate feature selection)
2.2.1 卡方检验 (chi_square)
2.2.2 互信息 (mutual_info)
2.2.3 皮尔逊相关系数 (Pearson correlation coefficient) - 2.3 从模型中进行特征选择 (select from model)
2.3.1 L1正则化 (L1-based feature selection)
2.3.2 随机森林 (Tree-based feature selection)
1 特征提取(Feature extration)
特征提取指通过特征组合的方式生成新特征的过程.这个组合可以是线性的(如,PCA),也可以是非线性的(如,PCA的非线性推广:KPCA)
1.1 主成分分析 (Principal Component Analysis, PCA)
1.2 核主成分分析 (Kernel Principal Component Analysis, KPCA)
1.3 线性判别分析 (LDA)
LDA与PCA最大的差别在于:PCA是无监督的,而LDA是有监督的; PCA着重描述特征,而LDA着重抓住其判别特征; 因此PCA变换矩阵是正交的,而LDA一般不是正交的(并不关注).
线性判别分析的核心思想
通过线性变换,使得变换后的矩阵对应的,不同类别的样本尽可能地分开.
什么叫尽可能分开呢?可以从两个方面来衡量.
1. 各类样本的类间方差尽可能大.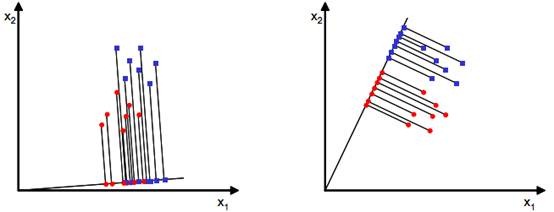
右方两类的样本中心较左方相隔更远,因此分类效果更好.
2. 各类样本的类内方差尽可能小.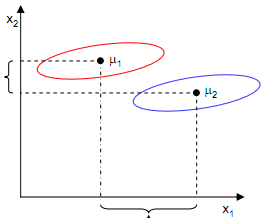
光考虑类间中心距离还是不够的.从上图可以看到,若投影到x1上,虽然两类中心相比投影到x2上,相隔较远.但由于两类在x1上的方差都很大,因此从分类角度看,效果比不上投影到x2上.
因此,必须同时考虑以上两方面才能达到我们想要的效果.
看,这其实就是方差分析的思想. 因此目标函数可以取统计意义上的F值.F值越大越好.目标优化函数
接下来我们要想,怎么量化这两个标准.
原始特征矩阵;
转换矩阵;
线性变换后的新矩阵.
其中,
n为样本数, p为特征数, d为变换后的特征数.使变换后各类样本的类间方差尽可能大.
变换后的各类样本中心:
其中,指第j类;
指第j类的样本数.
变换后的总体样本中心:
因此,变换后样本类间协方差矩阵 (Between-Class Scatter Matrix)可表示为:
显然,这是一个维的矩阵.
使变换各类样本的类内方差尽可能小.
样本类内协方差矩阵 (Within-Class Scatter Matrix)可表示为:目标函数
目标函数的展开
可以看到,我们现在的目标函数是由线行变换后的Y出发推出来的.我们更希望计算时能从X出发,因此,我们把代入目标函数.
可得:
1.
2.
3., 其中,
为原样本类间协方差矩阵
4., 其中,
为原样本类内协方差矩阵
5. 易得最终的目标优化函数:.该值越大越好.
目标优化函数求解
我们有了目标函数,接下来我们需要对其进行求解.
注意到,对变换矩阵W扩大C倍(C>0),方向没有改变.
因此我们可以只考虑时的情况,即对目标函数添加了一个条件.
这里大家可能会疑惑.上面不是说过,是一个
这是因为,我们希望能按判别能力从大到小依次找出W的每一维向量.那么取前d维就可以组成最终的变换矩阵W啦.(这有一丢丢类似PCA)
因此,在求解时,我们将W设置为的向量,那相应的,得到的
都将是一个常数
现在我们的目标函数变成了:
利用拉格朗日乘子,将条件与目标函数合并到一起,得到:
这显然是一个上凹函数,有且只有一个极大值.
因此,求偏导并令其为0:
若
看到了吧,是
的特征值;W是对应的特征向量. 因此,第i大的特征根对应的特征向量,就是W的第i个分量.取前d个特征向量合并,得到的就是W.
这里要注意的是,